URLS
Tutorial DirectoryWhat is a URL?

URL stands for Uniform Resource Locator. It is the Web address of an online resource, typically a Web site or document. A URL can have several different parts: a domain name, an extension, directories, a file, a query, parameters and a fragment.
What do Domain Names mean?

Domain Names. The Internet Corporation For Assigned Names and Numbers ( ICANN ) oversees all domain name registration. A domain name is selected and purchased by an individual or organization to reflect the identify of that person or organization. For example, 21cif stands for Twentyfirst Century Information Fluency, the name of the organization. Domain names literally can be anything that is not already used by someone else. They don't have to have any obvious meaning.
Domain Extensions. Each year sees a wealth of new domain extensions like .io, .web, .latino, .hotel, .madrid, and .fun. In 2009 there were close to 300 different domain extensions. That number has expanded dramatically. In 2016 it was close to 900. For an infographic of names up to 2016 see here. Some are country codes: .au (abbrevaition for Australia), .uk (United Kingdom) and .ca (Canada). Some are types of organizations: .creditunion and .institute. Others are special interests: .music, .motorcycles and .tennis. The most used extensions are still some of the oldest: .com (commmercial), .org (organizations), .edu (education), .gov (government) and .mil (military.
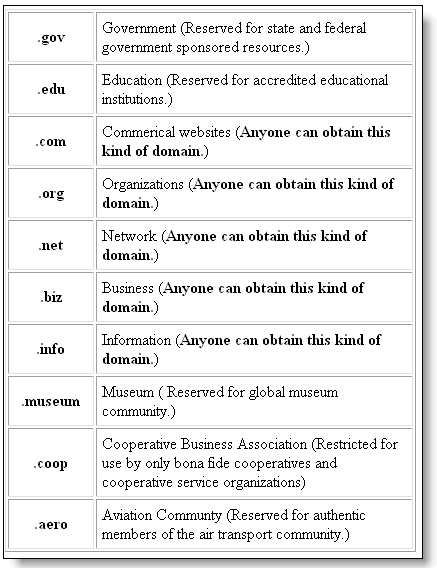
Domain names may tell you something about the publisher or owner of a Website.
It is important to note that most popular domain names can be acquired by anyone who is willing to pay a registrar. No publicly available domain name should automatically inspire trust, for example .org. Domains that are 'reserved' are more likely to be trustworthy, such as .edu (you can't buy one unless you are a college or university).
The content association for each domain is difficult to determine. Non-profit organizations and educational institutions may be registered under .com and .net domains. Many helpful social science pages are under the .gov domain. Generally speaking, if you don't recognize the domain extension (like .phd) you simply cannot assume it is associated with credible information or not. Investigative searching is required regardless of most domain extentions. You can always look up the meaning of an extension, but it does not tell you everything you need to know about a site. To determine credibility, investigate the author or publisher, freshness, content accuracy and what experts think of the information.
Make a habit of looking at ALL of the URL for sites you visit. Start with the root name. Is it the name you expect? Some pages redirect to other sites; unless you look at the domain name you may actually be viewing a different site than you assumed. If you are on cnn.com and click a link, make sure you know if you are still on cnn.com; if not, you could be on an advertiser's site.
Other parts of a URL
Directories and Files. Following the domain extension, you may notice forward slashes (/) separating terms. each slash is a directory (think file folder). For example, the page you are reading right now is http://21cif.com/tutorials/micro/mm/urls/index.html. This page is saved in a directory of tutorials which has some sub-directories including micro. Inside the micro directory is a sub-directory known as mm (micro modules) and inside that directory is a sub-directory called urls, the topic of this Micro Module. Finally there is the file name of the page: index.html. If you pay attention, you'll notice a lot of index.html pages on the 21cif site. Index.html is the default home page for the majority of directories and sub-directories.
Stated another way, there's an index.html page inside most directories on the site. A browser (like Firefox) reads the URL to locate the desired page within its directory. If there is no index.html in a directory, you may be able to see all the files in that directory.
Try this. truncate the URL back to this: http://21cif.com/tutorials/micro/mm/ -- notice that you can see a list of all files in the mm directory. Unless access is forbidden, this is usually the result of having no index.html file in a directory. If you are investigating a page, it is sometimes valuable to truncate the file name to see what else you can find in that directory.
Queries and Parameters. If you see a ? following the file name, it's a sign that information is being passed to the server through the URL. Here's a Google URL that shows the query 'information fluency': https://www.google.com/search?q=information+fluency&ie=utf-8&oe=utf-8. The parameters include q= (query) followed by the keywords separated by the google operator for AND. Following this is & (ampersand) and another parameter used to display content on the page. The ie is encoding for input; oe is encoding for the output. More on this here.
Looking a queries can sometimes provide important data for investigation. One example is the query for a file on a site which may not be found. If you copy the file name you may be able to google it and find the file on another site.
Fragments. A typical fragment includes the hashtag # and indicates a named anchor on a page--a specific location on the page. It's often used to take you to information without having to make you scroll to find it.
Try to take apart this URL: http://jobs.sciencecareers.org/jobs/chemistry/north-america/#browsing
This one has a subdomain: jobs. It's still part of the sciencecareers.org site. The page is about jobs in chemistry in North America. The #browsing is a named anchor that scrolls you to the top of the results. This is a pretty straightforward URL. Pay attention to URLs for investigative clues.
Authored by Carl Heine 2017